How to deploy
Once your flow is ready for production, you can deploy it as an API. Just click on deploy to get a production-ready version of your model.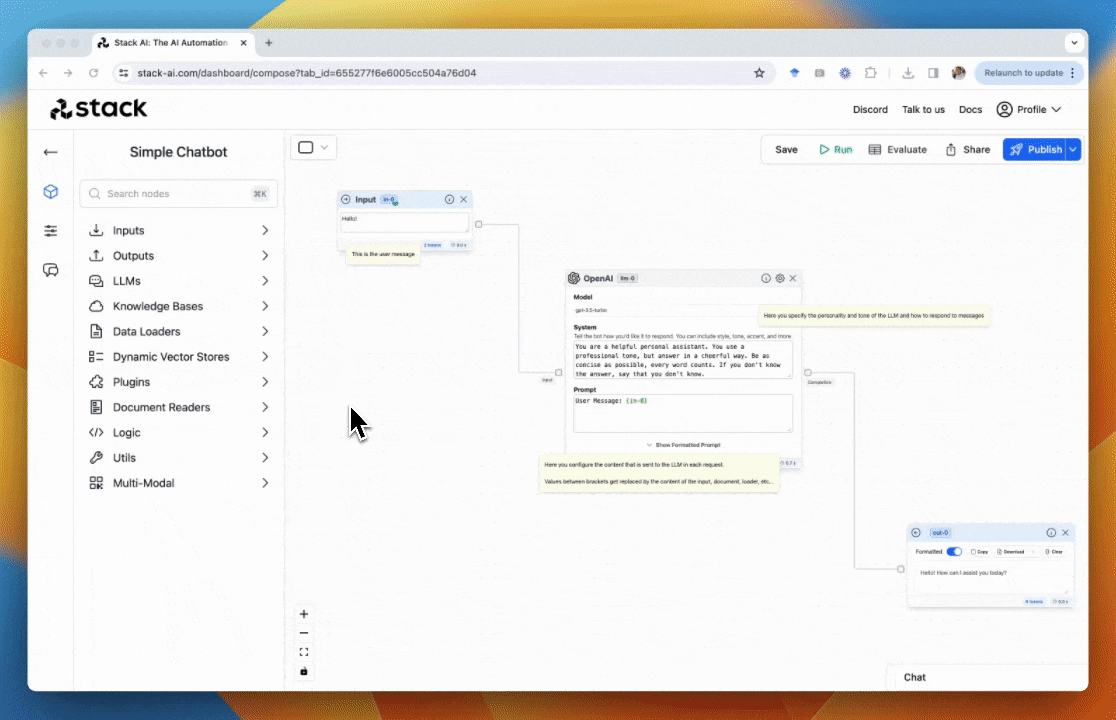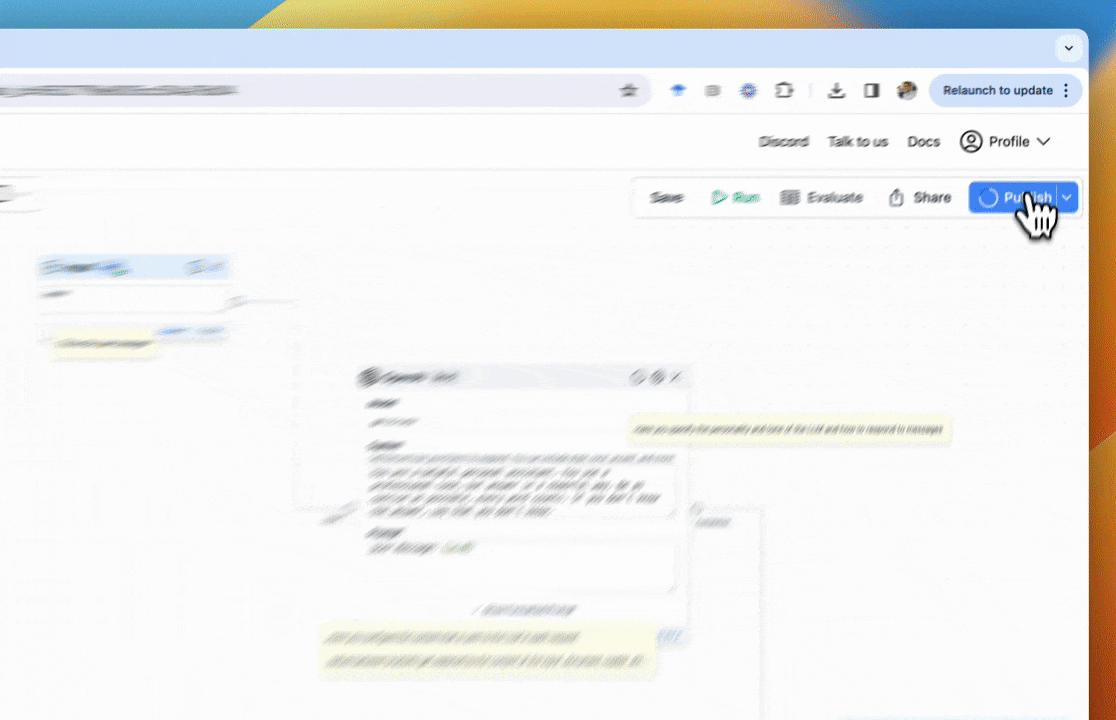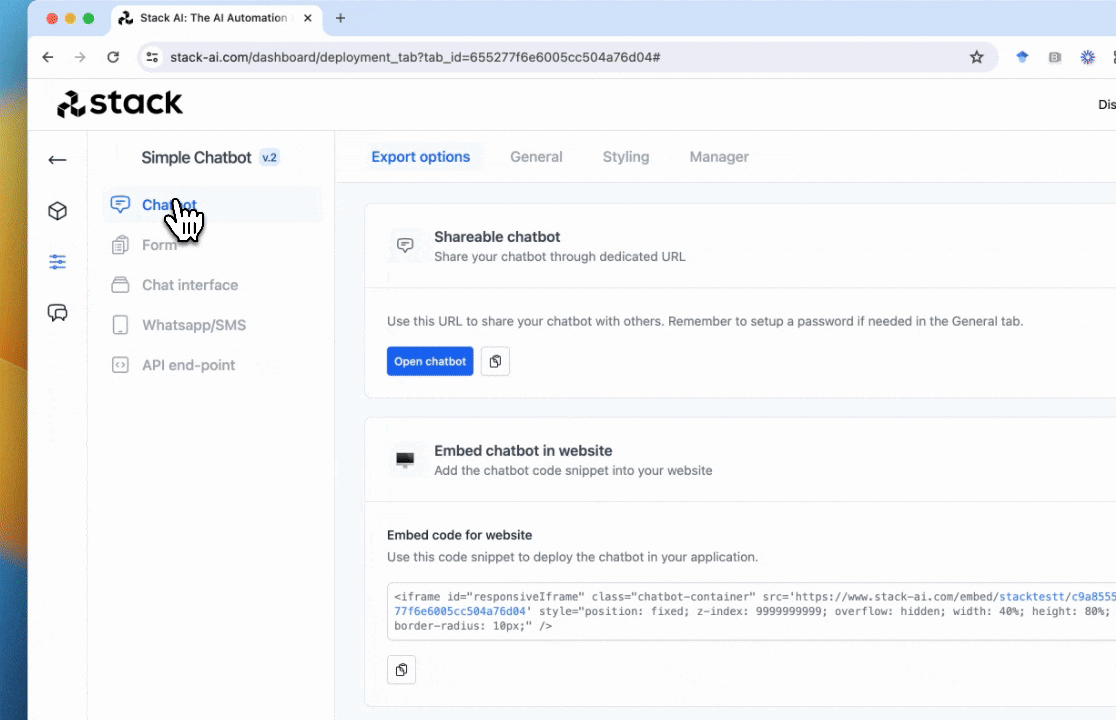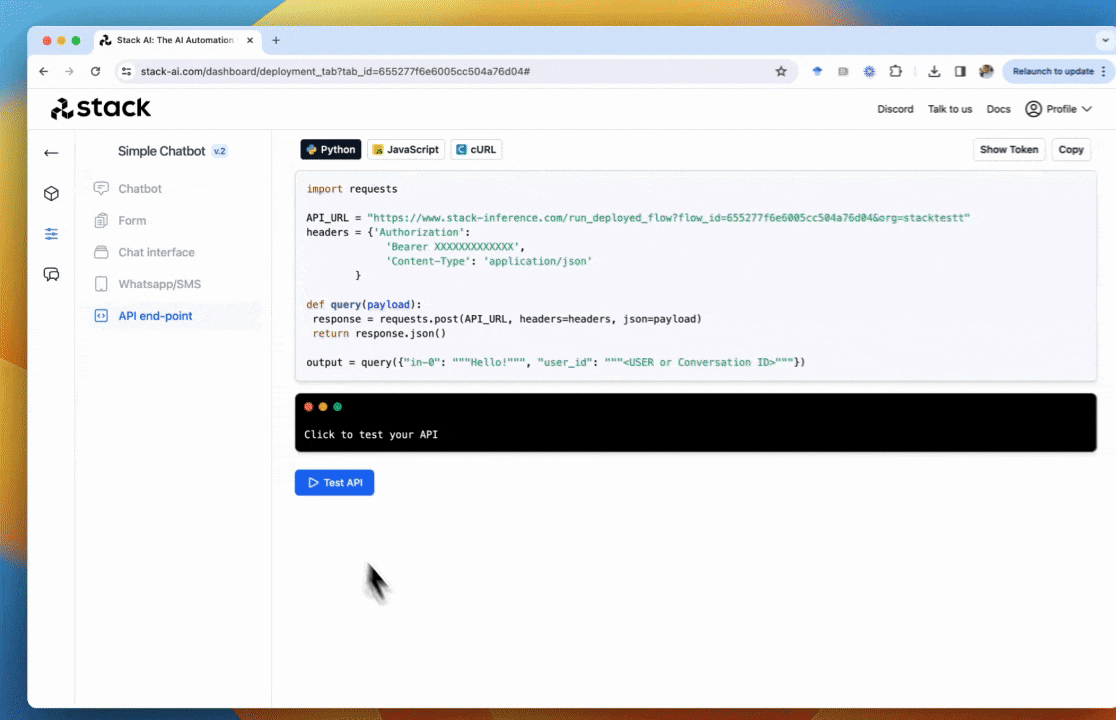
Get your RestAPI
To obtain your API just go to the deploy section of the Stack AI tool.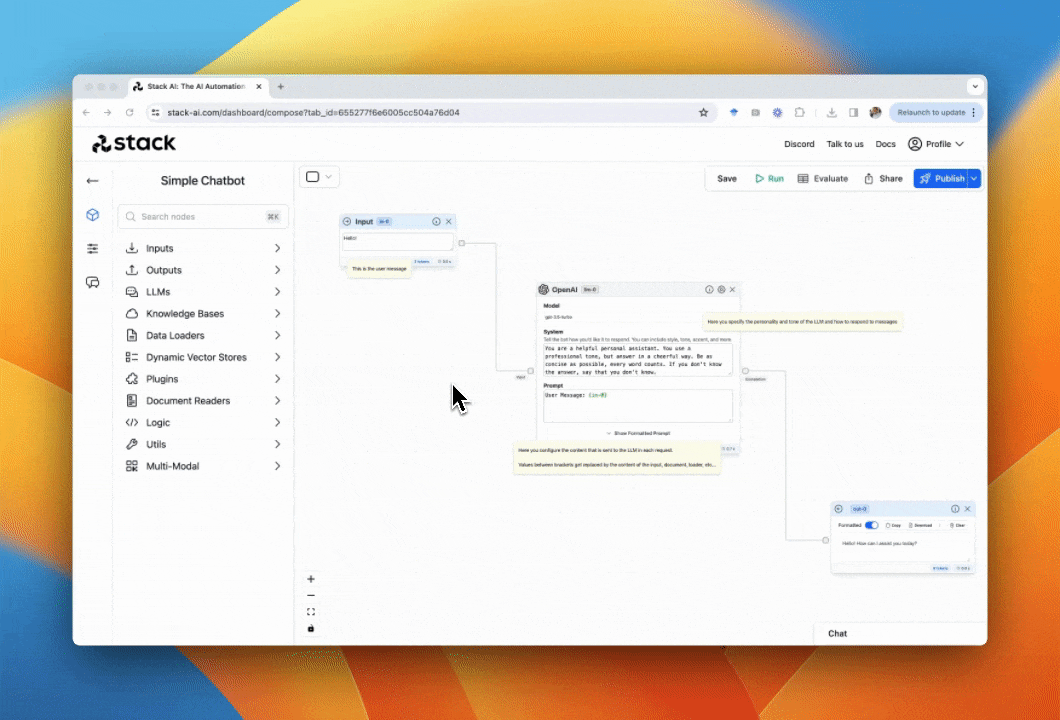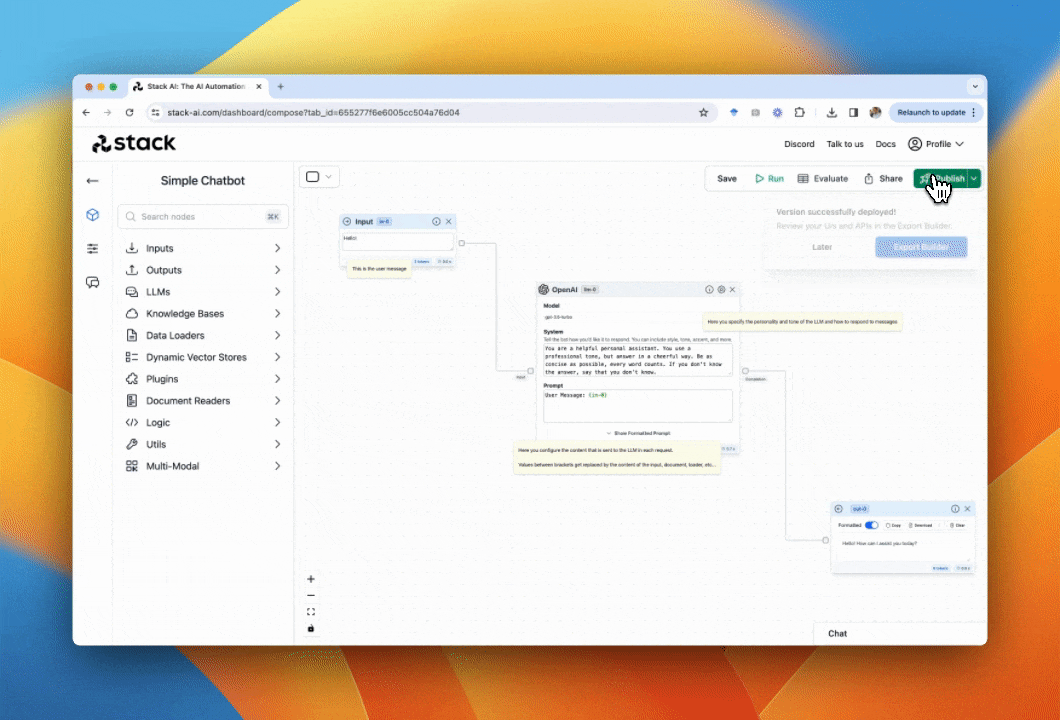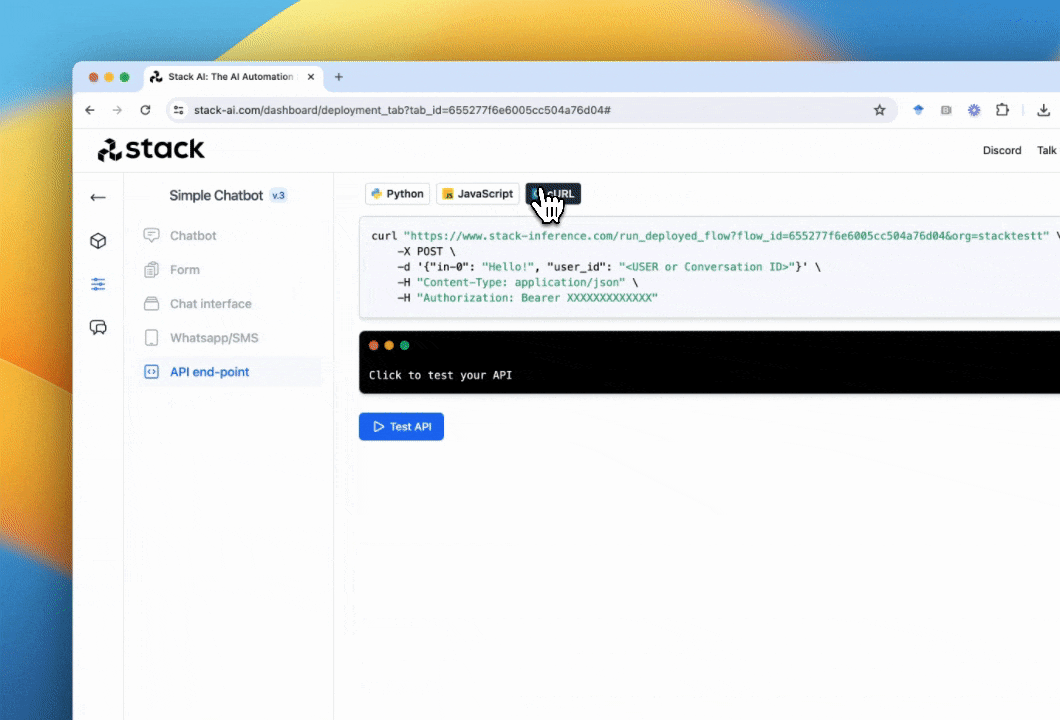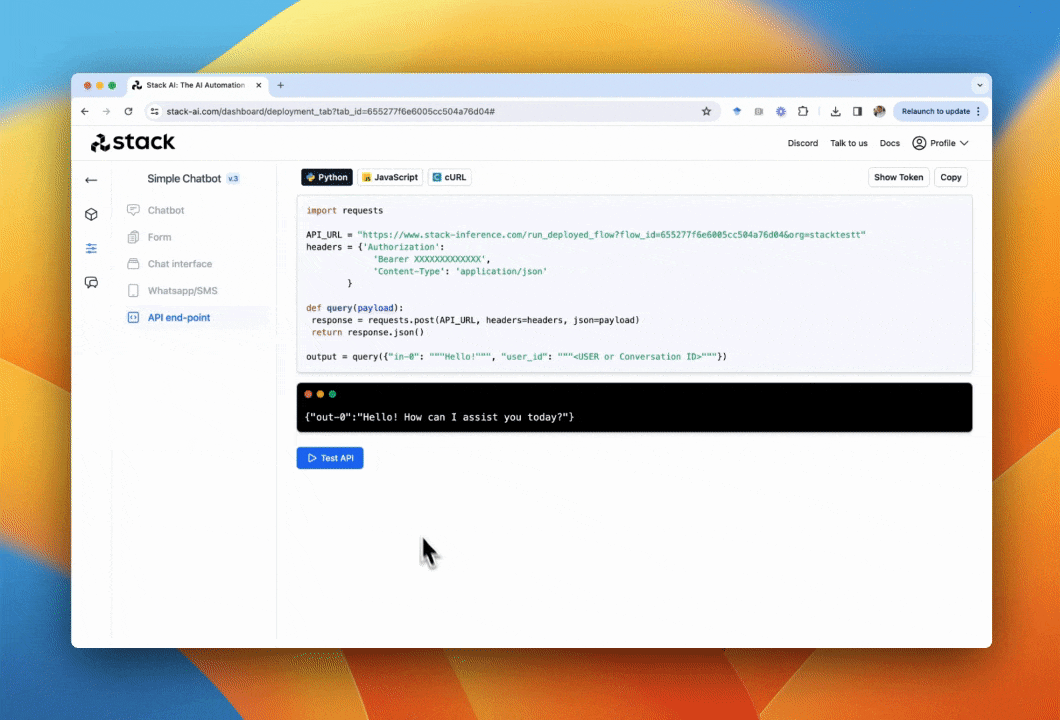 In this section, you will receive a code snippet to call your flow via a POST request in Python, JavaScript, and cURL.
In this section, you will receive a code snippet to call your flow via a POST request in Python, JavaScript, and cURL.
- This request receives all the inputs to the LLM as the body.
- This request returns the value of all the outputs to the LLM as a JSON.
- The API supports auto-scaling for a large volume of requests.
- Stack protects this API with the Token of your organization
Exposed Inputs
As part of your deployment, you can specify the following values as inputs in the request body:- Input nodes
in-. - User ID for LLM Memory
user_id- This value will create a database entry with the conversation history between each user and the LLM.
- String nodes
string-. - URL nodes
url-. - Inline document nodes
indoc-. - Image to Text
img2txt-. - Audio to Text Voice
audio2text-.