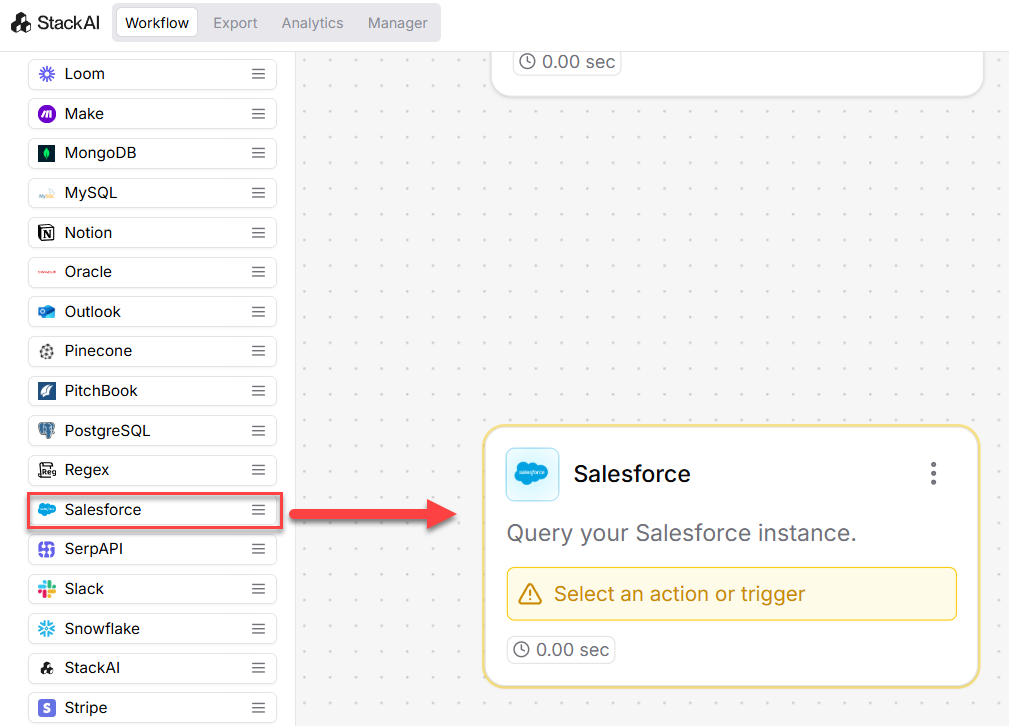
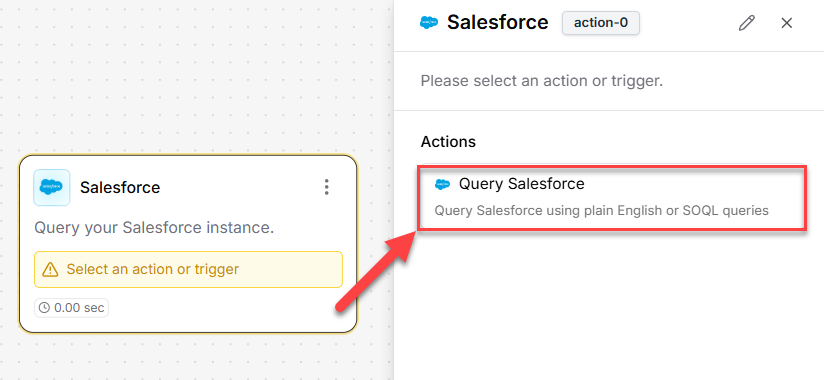
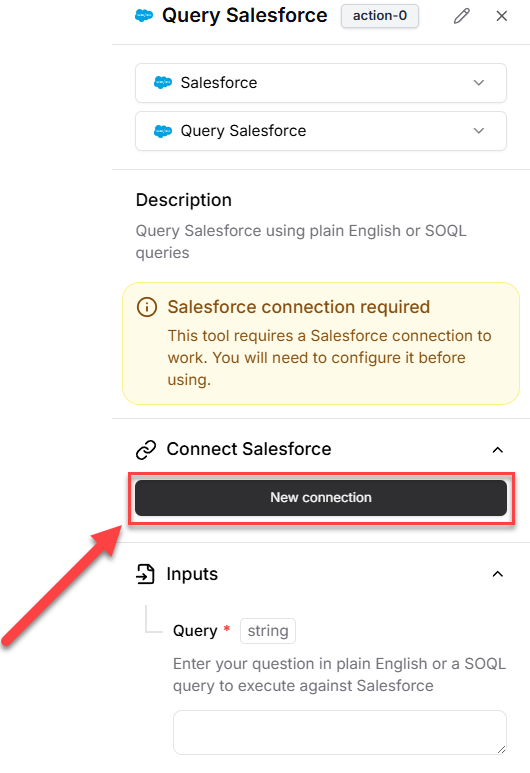
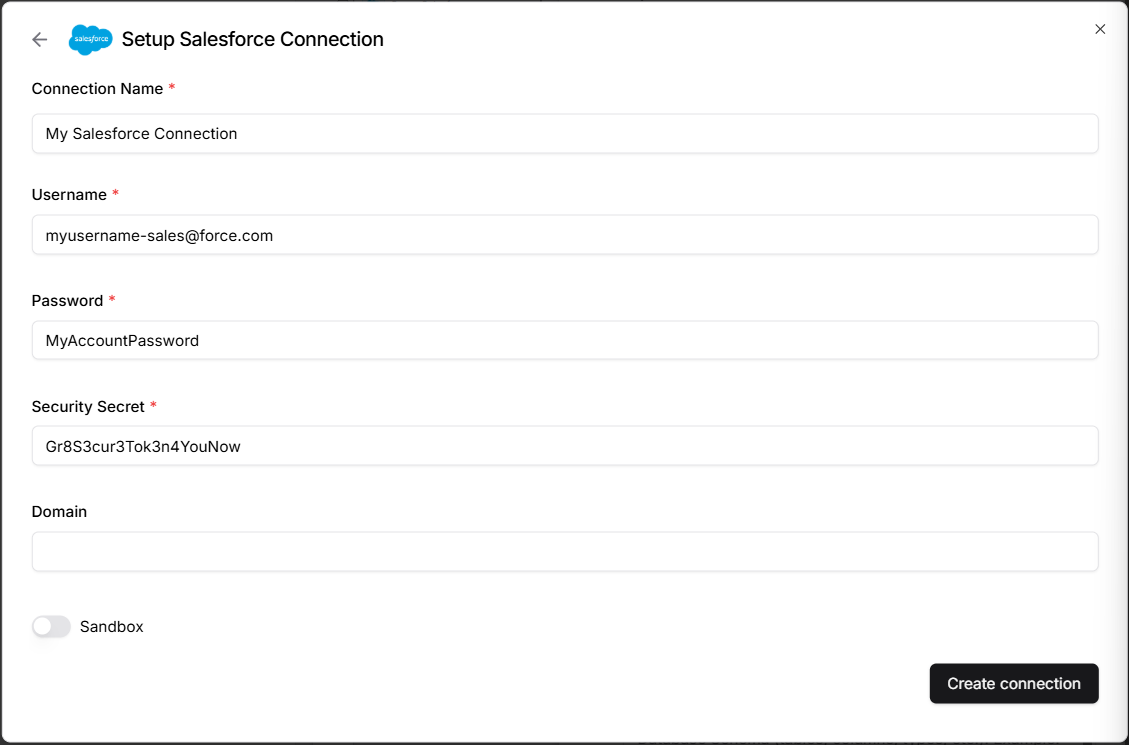
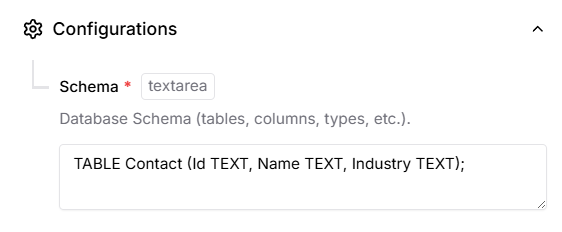
from simple_salesforce import Salesforce
# Salesforce credentials (replace with environment variables in production)
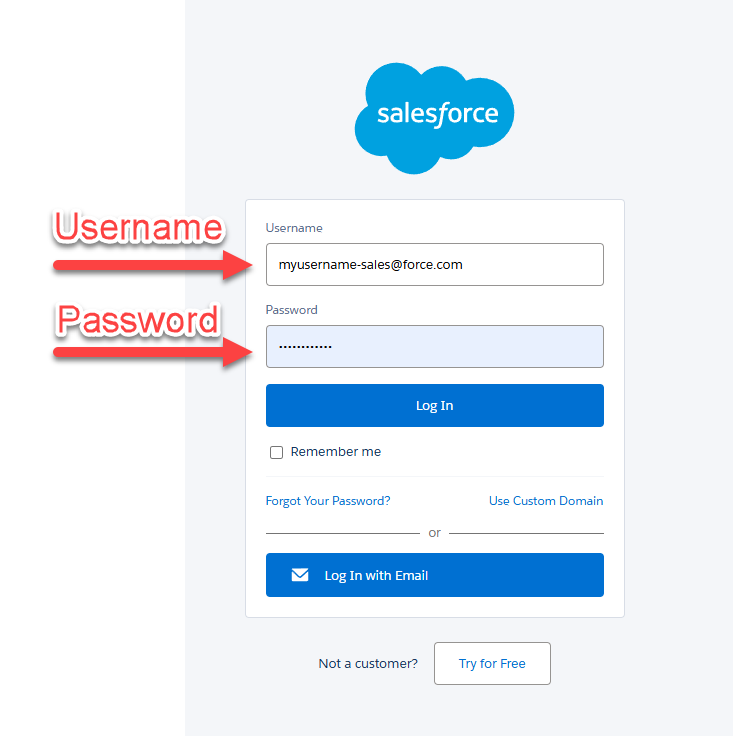
username = ""
password = ""
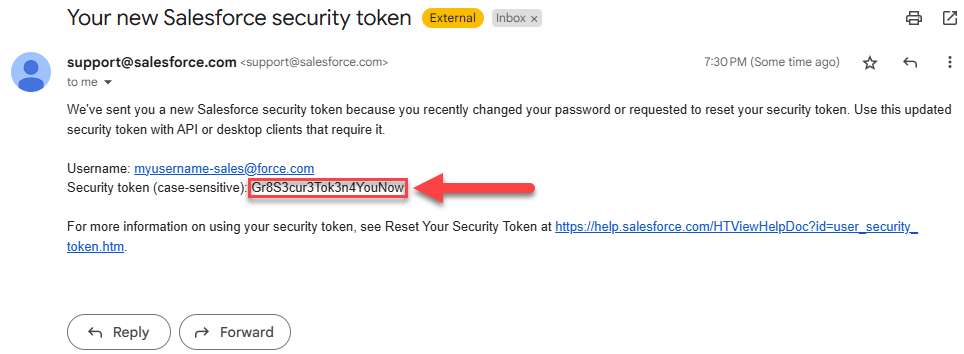
security_token = ""
# 🔍 Specify object names to include (DANGER leaving the list empty will include ALL)
included_objects = ["Contact", "Account", "Opportunity"] # Case-sensitive
# Connect to Salesforce
sf = Salesforce(username=username, password=password, security_token=security_token)
# Mapping Salesforce field types to SQL types
def map_salesforce_type(sf_type):
mapping = {
"string": "TEXT",
"textarea": "TEXT",
"picklist": "TEXT",
"id": "VARCHAR(18)",
"boolean": "BOOLEAN",
"int": "INTEGER",
"double": "FLOAT",
"currency": "DECIMAL(18,2)",
"percent": "DECIMAL(5,2)",
"date": "DATE",
"datetime": "TIMESTAMP",
"email": "TEXT",
"phone": "TEXT",
"url": "TEXT",
"reference": "VARCHAR(18)",
"base64": "BYTEA",
"location": "TEXT",
}
return mapping.get(sf_type, "TEXT")
# Get all object descriptions
objects = sf.describe()["sobjects"]
# Open file for writing schema output
with open("salesforce_schema.txt", "w") as file:
for obj in objects:
obj_name = obj["name"]
# Apply filter if specified
if included_objects and obj_name not in included_objects:
continue
try:
obj_details = sf.__getattr__(obj_name).describe()
field_defs = []
for field in obj_details["fields"]:
field_name = field["name"]
field_type = map_salesforce_type(field["type"])
field_defs.append(f"{field_name} {field_type}")
field_list = ", ".join(field_defs)
table_def = f"TABLE {obj_name} ({field_list});"
print(table_def)
file.write(table_def + "\n")
except Exception as e:
error_msg = f"-- Could not process {obj_name}: {e}"
print(error_msg)
file.write(error_msg + "\n")
print("\nFiltered schema has been saved to 'salesforce_schema.txt'")